Smart Data
El paso de la teoría a la práctica depende de cuán adecuada es la operacionalización de los conceptos y definiciones de la primera.
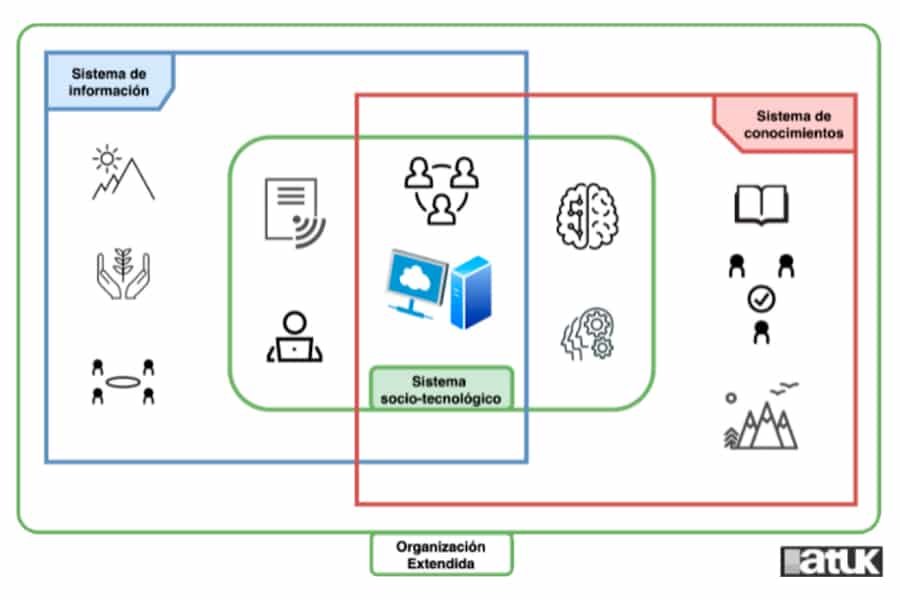
Smart Data, en la mayoría de los blogs, se considera como un proceso diferente al de Big Data, de apariencia más avanzada. Para nosotros, Smart Data es el producto mismo de Big Data. Mientras que Big Data es incluso un sistema de información, Smart Data es un subconjunto de datos e información descubierto y creado gracias a la operación de Big Data. Pero no es cualquier grupo de datos.
Algunos detalles sobre Big Data
Cuando detallamos qué es Big Data, llegamos, primero, a que es un cluster de tecnologías; segundo, a que es un proceso, incluso un paradigma, de análisis; y, finalmente, lo logramos entender como un sistema de información. Es decir, Big Data no se trata solo de computación (aunque la necesita sin duda alguna), sino de varios sistemas complejos, humanos y artificiales, trabajando y comunicándose entre sí. Así, Big Data es amplio, flexible y contextual y son estas características que hacen que pueda ser implementable en cualquier tipo de organización con sus particularidades propias.
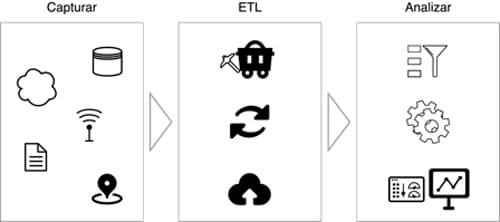
A grandes rasgos, el flujo de información en Big Data consta de tres etapas que son: Capturar, ETL y Analizar. La primera etapa registra y almacena grandes volúmenes de datos, de clases y formas muy variadas, a alta velocidad. Estas actividades son susceptibles a errores y ruido por lo que no todo lo que se captura es veraz o posee valor. Es por ello que la segunda etapa provee, entre otras, las actividades de preprocesamiento cuyo objetivo es limpiar y mejorar la calidad de los datos (García et al, 2015). Finalmente, la última etapa, cuando se usa y aplica modelamiento avanzado, es la que identifica, descubre o crea Smart Data.
¿Qué es Smart Data?
Según Kalinin et al (2015), Smart Data es el resultado de cualquier máquina inteligente o algoritmo de Machine Learning siempre y cuando Big Data haya sido extendido a Deep Data. Deep Data es un nivel más complejo de Big Data que se alcanza cuando se incorporan resultados teóricos y científicos. Esto es posible, por ejemplo, en física, biología, genética, etc. en donde ya se disponen de sistemas inteligentes como las Physics-Informed Neural Networks (Raissi, 2019, Qian et al, 2020, Karniadakis et al, 2021, entre otros) para el estudio de sistemas dinámicos complejos.
Sin embargo, según esta definición, las demás áreas del conocimiento humano que no poseen conocimientos formales sólidos y robustos no podrían permitirse esta extensión de Big Data y en consecuencia no gozar del resultado y el valor de Smart Data.
Teorías Middle-Range
En ciencias sociales, las teorías Middle-Range permiten consolidar hipótesis esparcidas y regularidades empíricas en cuerpos de conocimiento no tan abstractos y de no tan largo alcance (Bailey, 1991). Dicho de otra manera, debido a que no existe un gran cuerpo teórico robusto en ciencias sociales, el método más común es comenzar por abordar fenómenos empíricos específicos, plantear hipótesis de su causalidad teórica y finalmente validarlas usando datos (Merton & Merton, 1986). Aunque este se parece mucho al método científico, su alcance es mucho más limitado en generalidad, de ahí su nombre.
Regresando a la búsqueda de Smart Data, la incorporación de las teorías Middle-Range es una posible solución para aquellas ciencias, ingenierías y áreas del saber que no poseen cuerpos teóricos científicos altamente desarrollados. Es decir, no se trata de procesar datos por procesar, es necesario observar los fenómenos que ocurren en el contexto, en el día a día de las organizaciones, definir modelos que expliquen relaciones causales entre variables y, sobretodo, con el sistema de información Big Data verificar que esas relaciones sean las adecuadas. En efecto, no es una tarea sencilla.
Las particularidades de Smart Data
Smart Data está entre los dos macro componentes de todo sistema de información: en el sistema humano y el sistema computacional. Smart Data puede ser identificado en base a tres características que giran alrededor de su veracidad y su valor (García-Gil, 2019). Estas características son:
- Accuracy: calidad y precisión para generar valor organizacional.
- Actionability: permite definir acciones escalables que maximicen un objetivo organizacional.
- Agility: disponibilidad en tiempo real que permita la adaptación a las fluctuaciones del contexto organizacional.
Es decir, Smart Data está completamente arraigado a la organización y su contexto, ya que es altamente dependiente de su pertinencia para las personas que lo usan e interpretan. Si bien Smart Data se obtiene usando cuerpos teóricos para un modelamiento avanzado, este procedimiento garantiza su veracidad (sobre todo su accuracy). Mientras que su valor depende sin duda de las personas que toman decisiones (accuracy), fijan el rumbo (actionability) y conducen (agility) a la organización.
¿Para quién es Smart Data?
Nuevamente: para todo el equipo humano de la organización. Smart Data es lo más preciso posible, describe detalles operativos, tácticos y estratégicos de la organización. En efecto, no solo contiene valor estratégico, que permite fijar o adecuar los objetivos y políticas de largo plazo, sino también permite su operacionalización a cualquier grado de detalle, en cualquier departamento de la organización, a mediano y corto plazo.
En sí, la búsqueda de Smart Data es análoga a la de buscar una aguja en un pajar. Sin embargo, si damos con él, los beneficios organizacionales son inmensos. Su adquisición es difícil, pero no imposible. Demanda muchos recursos cognitivos y computacionales, pero sus características lo valen. Finalmente, hay que tener claro que un grupo de datos que califica como Smart Data en una determinada organización, podría no serlo para otra.
Referencias
Bailey, K. D. (1991). Alternative procedures for macrosociological theorizing. Quality and Quantity, 25(1), 37-55.
García, S., Luengo, J., & Herrera, F. (2015). Data preprocessing in data mining (Vol. 72). Cham, Switzerland: Springer International Publishing.
García-Gil, D., Luengo, J., García, S., & Herrera, F. (2019). Enabling smart data: noise filtering in big data classification. Information Sciences, 479, 135-152.
Kalinin, S. V., Sumpter, B. G., & Archibald, R. K. (2015). Big–deep–smart data in imaging for guiding materials design. Nature materials, 14(10), 973-980.
Karniadakis, G. E., Kevrekidis, I. G., Lu, L., Perdikaris, P., Wang, S., & Yang, L. (2021). Physics-informed machine learning. Nature Reviews Physics, 3(6), 422-440.
Merton, R. K., & Merton, R. C. (1968). Social theory and social structure. Simon and Schuster.
Qian, E., Kramer, B., Peherstorfer, B., & Willcox, K. (2020). Lift & Learn: Physics-informed machine learning for large-scale nonlinear dynamical systems. Physica D: Nonlinear Phenomena, 406, 132401.
Raissi, M., Perdikaris, P., & Karniadakis, G. E. (2019). Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378, 686-707.
¿Quieres suscribirte a nuestro boletin mensual?
Si deseas recibir información de alto valor, puedes dejarnos tus datos y te enviaremos mensualmente nuestro boletín informativo con todas las noticias relacionadas a ciencia, economía, sociedad y tecnología.