Gestión del conocimiento y Big Data
Como habíamos señalado en nuestro anterior artículo sobre Big Data, “Todo proyecto de Big Data se guía en un interés claro por parte de la organización o individuo que requiere solucionar, o al menos esclarecer, un problema dado”.
Esto permite considerar que los procesos en los que Big Data es necesario, son contextuales, incluso coyunturales, con respecto a la estrategia, los objetivos y las operaciones de una determinada organización.
En consecuencia, es importante considerar al Big Data como un eje de la Gestión de información y conocimiento. Pero antes, recordemos, primero, qué es conocimiento, información y datos; segundo, a qué hacemos referencia con el concepto de sistema de información; y, con todo esto, será más clara la relación entre Big Data y Gestión de información y conocimiento.
Datos-Información-Conocimiento
La relación datos-información-conocimiento es una relación incremental, evolutiva (Aduin et al, 2015; Javanmardi et al, 2021):
- Los datos hacen referencia a mediciones o registros del comportamiento o estado de una entidad de la realidad. El dato es fijo, incambiable, por que fue observado y registrado por un instrumento adecuado; como se presentó.
- Luego, los datos son transformados en información gracias a datos adicionales, llamados metadatos, que estructuran y moldean a los datos y que permiten interpretarlos por las personas. Es decir, la información, a grosso modo, son datos cargados de interpretación para una o más personas en un contexto personal, cultural y organizacional determinado.
- Finalmente está el conocimiento que es producido, modificado, intercambiado y posiblemente eliminado, gracias al procesamiento neuronal de las personas. El conocimiento moviliza personas para realizar cualquier actividad que esté dentro de sus capacidades
¿Qué es un sistema de información?
Un sistema de información no es solo un sistema computacional. En efecto, esta errada concepción proviene de una visión puramente tecnológica que mira al conocimiento como un objeto independiente de la persona que lo crea y usa, y que por tanto puede ser almacenado y transmitido. Es más, este mismo paradigma define a la Gestión del conocimiento en términos de procesos computacionales y bases de datos.
Sin embargo, un sistema de información, junto a un sistema de conocimientos, incluye un subsistema computacional, y se encuentra inmerso dentro del contexto de un super-sistema socio-tecnológico de una organización con personas, equipos, actividades y procesos específicos. Este es el enfoque gerencial y sociológico de la Gestión de información y conocimiento (Grundstein et al, 2014; Arduin et al, 2015; Grundstein, 2019). Aquí, el centro del sistema completo lo componen las personas y el subsistema digital informático, que no pueden ser separados de su contexto organizacional.
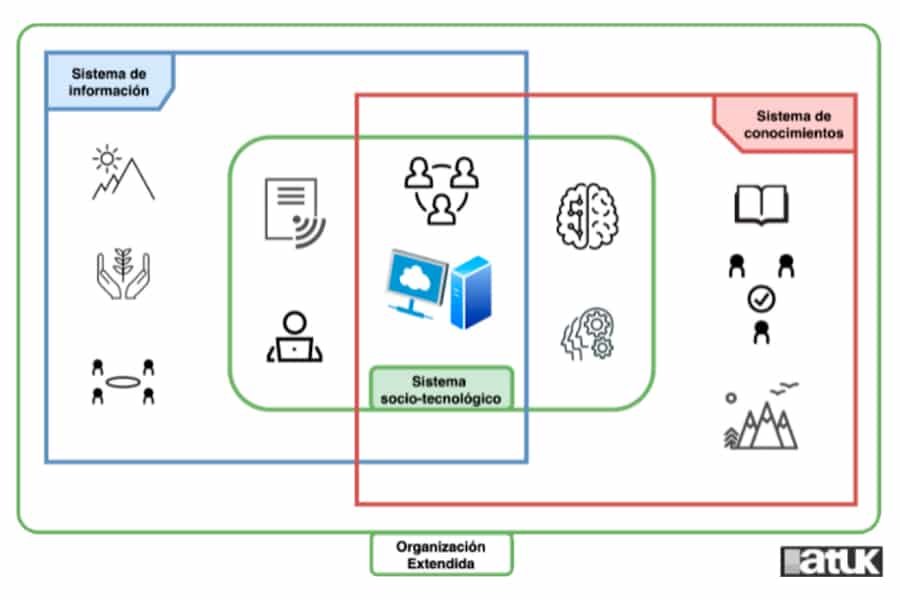
Esquema adaptado de Grundstein (2019, p.11).
Un sistema de información está compuesto, entre otros, por un subsistema computacional que ayuda a la transmisión, almacenamiento y difusión de datos, que serán transformados en información, es decir, interpretados, por el equipo humano y que finalmente permitirá a las personas crear conocimiento.
Un sistema computacional asegura la consistencia del trabajo de un equipo de la organización. Este es un artefacto basado en datos, información, computación, telecomunicaciones e inteligencia artificial (Atif, 2017).
Un sistema de conocimientos consiste, por un lado, de todo el conocimiento encarnado en las personas y, por otro lado, del codificado en cualquier forma física (fotos, texto, video, audio, etc.). Solo el conocimiento de esta última categoría puede ser transmitido, almacenado, procesado y difundido por el sistema computacional.
En resumen, un sistema de información completo interconecta a las personas que, en un contexto dado, acceden y procesan datos, gracias a un sistema computacional, y los dan sentido bajo la forma de información. Parte de esta información puede ser transmitida, almacenada, procesada y difundida por las mismas personas o por el sistema computacional. Es decir, la información es más que datos y, gracias al sistema de conocimientos, el conocimiento es más que información.
Big Data es un Sistema de información
Big Data no es una tecnología simple, incluso es más que un proceso: es un sistema de información. En efecto, Big Data no se puede reducir a una nueva, o vieja, tecnología o incluso varias. Big Data no se realiza sin objetivos e intereses claros y bien definidos. Big Data requiere un entorno organizacional. Big Data es conducido por personas con la ayuda de sub-sistemas computacionales.
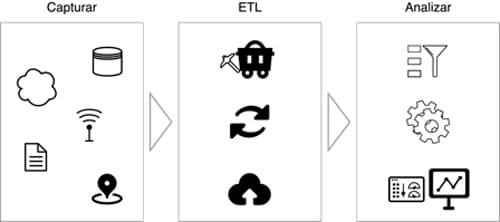
Las dos primeras etapas, Capturar y ETL, de Big Data como un proceso, han permitido la automatización de las tareas que más consumen recursos en el flujo de información. En 2016, Forbes reportó que la mayor parte (aprox. 80%) del esfuerzo de los analistas de datos se concentra en la preparación, limpieza y estructuración de datos. Este fenómeno sigue vigente, aunque con menor intensidad (aprox. 45%), según una encuesta realizada por Anaconda e informada por Datanami en 2020.
Sin embargo, la última etapa de Big Data, que es Analizar, nos permite observar que Big Data no puede ser completamente automatizable. En sí, esta etapa requiere los niveles cognitivos más profundos (Anderson & Krathwohl, 2001; Krathwohl, 2002) y por tanto la hace más dependiente de las capacidades y habilidades del equipo humano que consume los datos e información. Nos referimos a las capacidades analíticas, evaluativas y de creación de información. Un estudio empírico realizado por Harvard Business Review en 2018 muestra que las habilidades requeridas por los analistas no se centran en el uso de sistemas computacionales avanzados sino en el aprendizaje (humano) continuo coyuntural y la buena comunicación debido a que se requiere responder preguntas de interés organizacional explicando resultados complejos a actores no técnicos. Esto se refleja también en la actualidad en la encuesta de Anaconda (2020), en donde, cerca de un quinto del tiempo del analista (aprox. 21%) es invertido en la visualización de información. En fin, estos informes son confirmados por Dong & Triche (2020) que muestra que la bolsa de empleo de analistas de datos demandan cada vez más capacidades en la gestión y manejos de datos (aprox. 50%) y conocimientos estadísticos y capacidades de modelamiento y estructuración de datos (aprox. 50%).
En conclusión, una mirada detallada hacia Big Data nos revela que este trasciende las fronteras de un simple concepto o tecnología, supera la definición de paradigma teórico al encajar pertinentemente en el marco práctico de la Gestión del conocimiento como un sistema de información dotado de varios subsistemas computacionales y tecnológicos interoperables cuyo propósito es la efectiva difusión de datos hacia las personas adecuadas que los interpretarán y convertirán en información para, posteriormente, generar nuevo conocimiento personal y social, extendiendo sin duda el contexto organizacional en donde está inmerso.
Referencias
Anderson, L. W., & Krathwohl, D. R. (2001). A taxonomy for learning, teaching, and assessing: A revision of Bloom’s taxonomy of educational objectives. Longman.
Arduin, P. E., Grundstein, M., & Rosenthal-Sabroux, C. (2015). Information and knowledge systems (Vol. 2). ISTE.
Atif, L. (2017). P©, une approche collaborative d’analyse des besoins et des exigences dirigée par les problèmes: le cas de développement d’une application Analytics RH (Doctoral dissertation, PSL Research University).
Dong, T. & Triche, J. (2020). A Longitudinal Analysis of Job Skills for Entry-Level Data Analysts. Journal of Information Systems Education, 31(4), 312-326.
Grundstein, M., Arduin, P. E., & Rosenthal-Sabroux, C. (2014). From Information System to Information and Knowledge System. In Italian Chapter of the Association for Information Systems (itAIS).
Grundstein, M. (2019). Toward Management Based on Knowledge. In Current Issues in Knowledge Management. IntechOpen.
Javanmardi, E., Liu, S., & Xie, N. (2021). Exploring the philosophical foundations of grey systems theory: Subjective processes, information extraction and knowledge formation. Foundations of Science, 26(2), 371-404.
Krathwohl, D. R. (2002). A revision of Bloom’s taxonomy: An overview. Theory into practice, 41(4), 212-218.
¿Quieres suscribirte a nuestro boletin mensual?
Si deseas recibir información de alto valor, puedes dejarnos tus datos y te enviaremos mensualmente nuestro boletín informativo con todas las noticias relacionadas a ciencia, economía, sociedad y tecnología.